Markus Strasser
Powered by 🌱Roam GardenShort Plunge into Snorkel, Weak Supervision and Data Augmentation
excerpt::
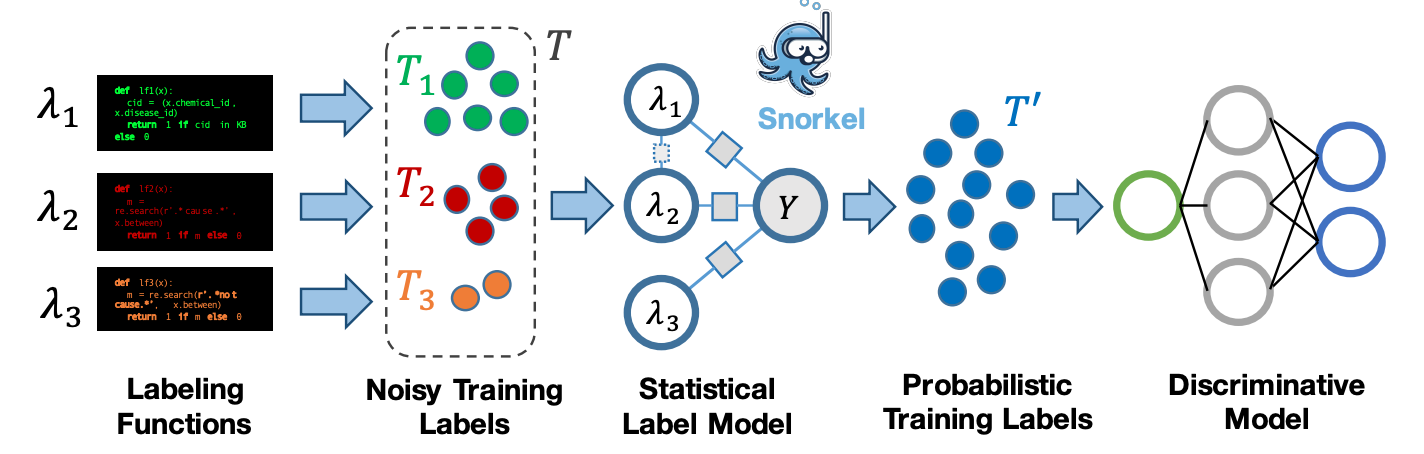
Three principles that have shaped Snorkel’s design:
- Bring All Sources to Bear
The system should enable users to opportunistically use labels from all available weak supervision sources.
- Training Data as the Interface to ML
The system should model label sources to produce a single, probabilistic label for each data point and train any of a wide range of classifiers to generalize beyond those sources.
- Supervision as Interactive Programming
The system should provide rapid results in response to user supervision. We envision weak supervision as the REPL-like interface for machine learning.
Declarative Operator DSL and Templates
Declarative Labeling Functions
Snorkel includes a library of declarative operators that encode the most common weak supervision function types, based on our experience with users over the last year.
The semantics and syntax of these operators is simple and easily customizable, consisting of two main types: (i) labeling function templates, which are simply functions that take one or more arguments and output a single labeling function; and (ii) labeling function generators, which take one or more arguments and output a set of labeling functions (described below). These functions capture a range of common forms of weak supervision, for example:

Ontology Based Labeling Function Example
In our running example, we can use the Comparative Toxicogenomics Database (CTD) as distant supervision, separately modeling different subsets of it with separate labeling functions. For example, we might write one labeling function to label a candidate True if it occurs in the “Causes” subset, and another to label it False if it occurs in the “Treats” subset. We can write this using a labeling function generator,

which creates two labeling functions. In this way, generators can be connected to large resources and create hundreds of labeling functions with a line of code.
Code-As-Supervision
This code-as-supervision approach can then inherit the traditional advantages of code such as modularity, debuggability, and higher-level abstraction layers. In particular, enabling this last element—even higher-level, more declarative ways of specifying labeling functions—has been a major motivation of the Snorkel project.
Post-Symbolic Labeling Functions
One idea, motivated by the difficulty of writing labeling functions directly over image or video data, is to first compute a set of features or primitives over the raw data using unsupervised approaches, and then write labeling functions over these building blocks.
For example, if the goal is to label instances of people riding bicycles, we could first run an off-the-shelf pre-trained algorithm to put bounding boxes around people and bicycles, and then write labeling functions over the dimensions or relative locations of these bounding boxes.Footnote20
In medical imaging tasks, anatomical segmentation masks provide a similarly intuitive semantic abstraction for writing labeling functions over. For example, in a large collection of cardiac MRI videos from the UK Biobank, creating segmentations of the aorta enabled a cardiologist to define labeling functions for identifying rare aortic valve malformations [17].
An even higher-level interface is natural language. The Babble Labble project accepts natural language explanations of data points and then uses semantic parsers to parse these explanations into labeling functions. In this way, users without programming knowledge have the capability to write labeling functions just by explaining reasons why data points have specific labels. Another related approach is to use program synthesis techniques, combined with a small set of labeled data points, to automatically generate labeling functions
@labeling_function()
One of the core challenges in any type of programmatic or weak supervision is handling noisy sources of labels (e.g. LFs) that may have varying accuracies, correlations, and broadly overlap and conflict with each other.
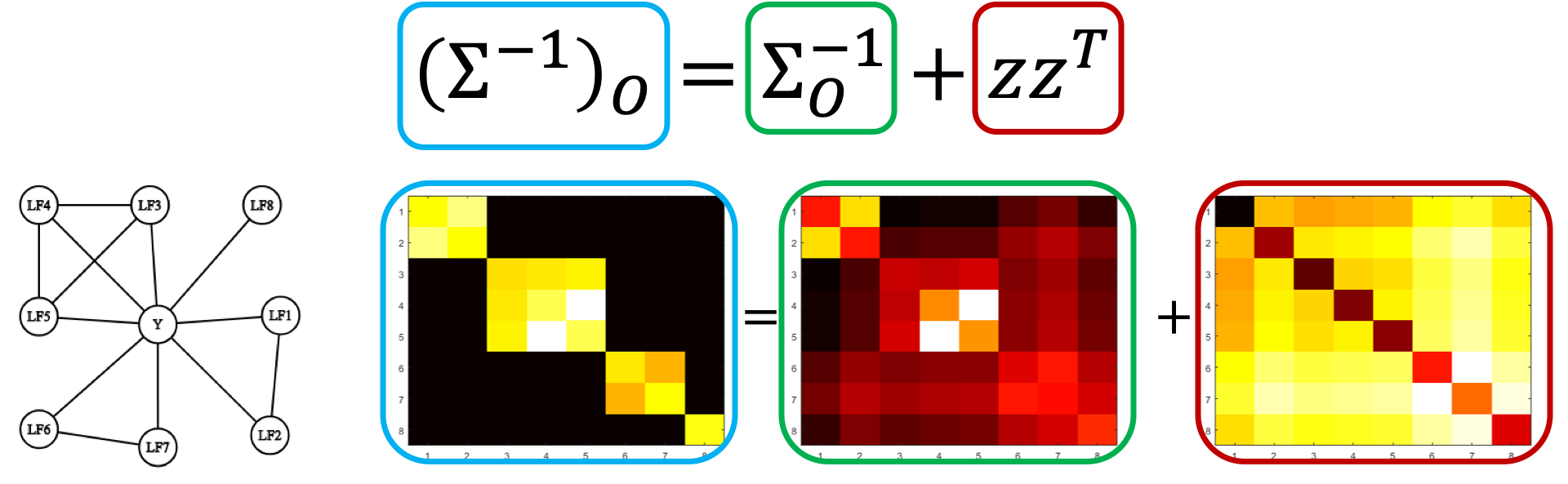
In v0.9, we switch to a new matrix completion-style approach based on our work in AAAI 2019. This new approach leverages the graph-structured sparsity of the inverse generalized covariance matrix of the labeling functions’ outputs to reduce learning their accuracies and correlation strengths to a matrix completion-style problem. This formulation is far more scalable (scaling with the number of labeling functions rather than dataset size!), cleaner to implement more complex models of the labeling process in, and comes with sharper theoretical guarantees.
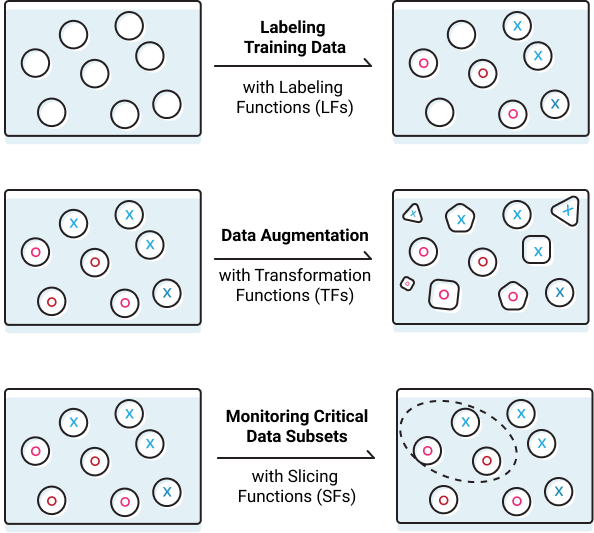
key abstractions: labeling function vs. Transformation Functions vs. Slicing Functions
Google reportedly reduced one of its translation code bases from 500 thousand to ~500 lines of code
It has become commonplace for individuals and organizations alike to quickly spin up high-performing machine learning-based applications where years of effort might have once been required.
Ludwig (uber): Testing models
Hidden Stratification: As machine learning models get deployed in more real-world applications, we may need to be wary of problems like hidden stratification and develop methods to help us build better confidence in our models.
Understanding Embeddings: Pre-trained embeddings are ubiquitous in machine learning deployments, but questions like when embeddings should be used, how exactly they provide lift, and what geometries to use for different applications are still poorly understood.
We thus propose the eigenspace overlap score as a new measure
Snorkel and Flying Squid
Snorkel: Use all These Methods together! distant supervision Regular Expression for heuristic training sets

data programming is similar to programmatic labeling
excerpt::
REPL based ML Development
Our goal is to enable machine learning systems to be trained interactively. This requires models that perform well and train quickly, without large amounts of hand-labeled data.
With Pretrained-Embeddings You Get REPL Speed
But WS relies on training downstream deep networks to extrapolate to unseen data points, which can take hours or days. Pre-trained embeddings can remove this requirement.
We do not use the embeddings as features as in transfer learning (TL), which requires fine-tuning for high performance, but instead use them to define a distance function on the data and extend WS source votes to nearby points.
Unfortunately writing useful label functions requires substantial error analysis and is a nontrivial task: in early efforts to use data programming we found that producing each label function could take a few days. Producing a biomedical knowledge base with multiple node and edge types could take hundreds or possibly thousands of label functions. In this paper we sought to evaluate the extent to which label functions could be re-used across edge types.
Different from existing hetnets like Hetionet where text-derived edges generally cannot be exactly attributed to excerpts from literature [3,72], our approach would annotate each edge with its source sentences. In addition, edges generated with this approach would be unencumbered from upstream licensing or copyright restrictions, enabling openly licensed hetnets at a scale not previously possible [73,74,75]. Accordingly, we plan to use this framework to create a robust multi-edge extractor via multitask learning [68] to construct continuously updating literature-derived hetnets.
Learns a Label Function Accuracy without Ground Truth?
We can model the outputs of the labeling functions (along with the unseen label) as a latent variable model. How is it possible to learn the parameters of a such a model without ever observing one of its components? Remarkably, sufficient signal is provided by independence. That is, we need some of our labeling functions to be independent conditioned on the true label.
3. Partitioning data with slicing functions
In many datasets, especially in real-world applications, there are subsets of the data that our model underperforms on, or that we care more about performing well on than others. For example, a model may underperform on lower-frequency healthcare demographics (e.g. younger patients with certain cancers) or we may care extra about model performance on safety-critical but rare scenarios in an autonomous driving setting, such as detecting cyclists. We call these data subsets slices. The technical challenge often faced by practitioners is to improve performance on these slices while maintaining overall performance.
Slicing functions (SFs) provide an interface for users to coarsely identify data subsets for which the model should commit additional representational capacity. To address slice-specific representations, practitioners might train many models that each specialize on particular subsets, and then combine these with a mixture-of-experts (MoE) approach [6]. However, with the growing size of ML models, MoE is often impractical.
As a quick overview 5 — we model slices in the style of multi-task learning, in which slice-based “expert-heads” are used to learn slice-specific representations. Then, an attention mechanism is learned over expert heads to determine when and how to combine the representations learned by these slice heads on a per-example basis.
From WiC error analysis, we might find that our model appears to perform worse on examples where the target word is a noun instead of a verb. Using an SF, we tell the model to pay attention to the differences between these slices and use a slightly different representation when making predictions for target words that it believes are nouns.
Extracting chemical reactions from text using Snorkel

GAN Generative Adversarial Data Programming
Recent work (Data Programming) has shown how distant supervision signals in the form of labeling functions can be used to obtain labels for given data in near-constant time. In this work, we present Adversarial Data Programming (ADP), which presents an adversarial methodology to generate data as well as a curated aggregated label, given a set of weak labeling functions.
More interestingly, such labeling functions are often easily generalizable, thus allowing our framework to be extended to different setups, including self-supervised labeled image generation, zero-shot text to labeled image generation, transfer learning, and multi-task learning.